Pynini: Grammar compilation in Python 
Introduction
Pynini (Gorman 2016) is a library for compiling a grammar of strings, regular expressions, and context-dependent rewrite rules into weighted finite-state transducers.Design
Pynini supports much of the functionality of Thrax, but whereas Thrax is essentially a compiler for a domain-specific language, Pynini is implemented as a Python extension module. This provides several advantages:- Pynini users can exploit Python's rich tooling ecosystem, including logging and unit testing frameworks.
- Pynini users can incorporate Thrax primitives like string compilation into executables.
Outline
This document covers the following areas:- formal preliminaries underlying finite-state transducers,
- getting started with Pynini,
- examples of Pynini in action, and
- advanced topics.
Formal preliminaries
Finite-state transducers (FSTs) are models of computation widely used for speech and language processing:- Speech recognition: language models, the pronunciation dictionaries, and the lattices produced by the acoustic model are all represented as FSTs; combined, these define the hypothesis space for the recognizer.
- Speech synthesis: FSTs are used for text normalization, the phase of linguistic analysis that converts written text like "meet me at St. Catherine on Bergen St. @ 9:30" to a pronounceable utterance like "meet me at the Saint Catherine on Bergen Street at nine thirty".
- Natural language processing: FSTs are used to represent sequence models such as those used for part of speech tagging, noun chunking, and named entity recognition.
- Information retrieval: finite automata are used to detect dates, times, etc., in web text.
State machines
Finite automata are simply state machines with a finite number of states. And, a state machine is any devices whose behavior can be modeled using transitions between a number of states. While our finite automata are implemented in software, there are also hardware state machines, like the traditional gumball machine (image credit: Wikimedia Commons): A working gumball machine can be in one of two states: either its coin slot does, or does not, contain a coin. Initially the gumball machine has an empty coin slot; and turning the knob has no effect on the state of the machine. But once a coin is inserted into the coin slot, turning the knob dispenses a gumball and empties the coin slot. If the knob is turned while the coin slot is vacant, no change of state occurs. However, if the knob is turned while the coin slot is occupied, a gumball is dispensed and the coin slot is cleared. We can represent this schematic description of a gumball machine as a directed graph in which the states are represented by circles and the transitions between states—henceforth, arcs—are represented by arrows between states. Each arc has a pair of labels representing the input consumed, and output emitted, respectively, when that arc is traversed. By convention, the Greek letter ε (epsilon) is used to represent null input and/or output along an arc.
A working gumball machine can be in one of two states: either its coin slot does, or does not, contain a coin. Initially the gumball machine has an empty coin slot; and turning the knob has no effect on the state of the machine. But once a coin is inserted into the coin slot, turning the knob dispenses a gumball and empties the coin slot. If the knob is turned while the coin slot is vacant, no change of state occurs. However, if the knob is turned while the coin slot is occupied, a gumball is dispensed and the coin slot is cleared. We can represent this schematic description of a gumball machine as a directed graph in which the states are represented by circles and the transitions between states—henceforth, arcs—are represented by arrows between states. Each arc has a pair of labels representing the input consumed, and output emitted, respectively, when that arc is traversed. By convention, the Greek letter ε (epsilon) is used to represent null input and/or output along an arc.
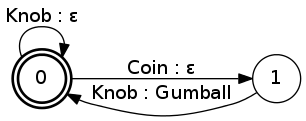 The bold double-circle state labeled
The bold double-circle state labeled 0 simply indicates that that state is "final", whereas the single-circle state 1 is non-final. Here, this encodes the notion that no user would walk away from a gumball machine while there's still a coin in the slot.
Finite-state acceptors
In what follows, we draw heavily from chapter 1 of Roark & Sproat 2008, and interested readers are advised to consult that resource for further details.Definition
Finite-state acceptors (or FSAs) are the simplest type of FST. Each FSA represents a set of strings (henceforth, a language), similar to a regular expression, as follows. An FSA consists of a five-tuple (Q, S, F, Σ δ) where:- Q is a finite set of states,
- S is the set of start states,
- F is the set of final states,
- Σ is the alphabet, and
- δ : Q × (Σ ∪ ε) → Q is the transition relation.
- The source state for p0 is in S,
- δ(qi li) = qi + 1 for any pi = (qi, li, qi + 1) ∈ P, and
- the destination state for pn is in F.
Example
The following FSA represents the Perl-style regular expressionab*cd+e:
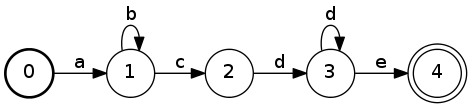 Here, the bold circle labeled
Here, the bold circle labeled 0 indicates the start state, and the double
circle labeled 4 indicates the final state.
Finite-state transducers
Definition
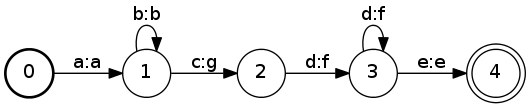
Finite-state transducers (FSTs) are generalization of FSAs. In the normal case of a two-way transducer, δ is instead a relation from Q × (Σi ∪ ε) × (Σo ∪ ε) → Q where Σiand Σo are the input and output alphabets, respectively. Paths through a FST are defined similarly to the definition given for FSAs above, except that each path corresponds to a set of two strings, an input string over Σi* and an output string over Σo*. Whereas FSAs describe sets of strings, FSTs describe relations between sets of strings. When the relation described by an FST is such that each input string corresponds to at most one output string, we say that the FST is functional.Example
The following FST represents the relation(a:a)(b:b)*(c:g)(d:f)+(e:e):
Weighted finite-state transducers
Definition
Weighted finite-state transducers (WFSTs) are generalizations of FSTs which use an alternative definition of both F and δ incorporating the notion of weights. FST weights and their operations can be understood by first defining the notion of semiring, which require us to first define the notion monoid. A monoid is a pair (M, •) where M is a set and • is a binary operation on M such that:- • is closed over M: for all a, b in M, a • b ∈ M,
- there is an identity element e ∈ M such that a • e = e • = a for all a ∈ M, and
- • is associative; for all a, b, c ∈ M, (a • b) • c = a • (b • c).
- (𝕂, ⊕) is a commutative monoid,
- (𝕂, ⊗) is a monoid,
- for all a, b, c ∈ 𝕂, a ⊗ (b ⊗ c) = (a ⊗ b) ⊕ (a ⊗ c), and
- for all a ∈ 𝕂, a ⊗ 0 = 0 ⊗ a = 0 where 0 is the identity element for the monoid (𝕂, ⊕).
standard arc type) is the default semiring in Pynini.
At last, we can give the modified definitions for F and delta; for WFSTs. Whereas for unweighted FSTs, F is a set of final states, for WFSTs F is a set of pairs over Q × 𝕂, where the second element is the final weight for that state. And, the transition relation δ for a WFST is from Q × (Σi ∪ ε) × (Σo ∪ ε) × 𝕂 to Q. The definition of paths is parallel to those for unweighted FSTs except that each element in the path is also associated with a weight in 𝕂.
Example
WFSTs are a natural representation for conditional probability distributions from strings to strings. For example, consider a text normalization rule which verbalizes2:00 as two with P = .2 and as two o'clock with P = .8. The following probability (i.e., real-valued) semiring WFST encodes this distribution:

Conventions used in Pynini
- Pynini represents all acceptors and transducers, weighted or unweighted, as WFSTs. Thus, for example, a weighted finite-state acceptor (WFSA) is represented as a WFST in which input and output labels match in all cases, and an unweighted finite-state transducer is represented by a WFST in which all weights are 1 or 0.
- Pynini only permits one state to be designated the start state.
- Pynini assigns a final weight to all states; a nonfinal state is just one which has a final weight of 0.
Getting started with Pynini
Starting Pynini
Install Pyniniimport pynini
Building FSTs
In Pynini, all FST objects are an instance of a class calledpynini.Fst, representing a mutable WFST. The user must specify the arc type at construction time; by default, the standard arc type (and the associated tropical semiring) is are used.
Pynini provides several functions for compiling strings into FSTs; we proceed to review a few of these methods.
Constructing acceptors
Theacceptor function compiles a (Unicode or byte) string into a deterministic acceptor. The user may specify a final weight using the weight keyword argument; by default, the final weight is 1. The user may also specify the desired arc type using the arc_type keyword argument. The user may also specify how the characters in the string are to be translated into labels of the acceptor. By default (token_type="byte"), each arc in the acceptor corresponds to byte in the input string.
# UTF-8 bytestring, byte arcs.
print pynini.acceptor("Pont l'Evêque")
# Output below...
0 1 P 1 2 o 2 3 n 3 4 t 4 5 <SPACE> 5 6 l 6 7 ' 7 8 E 8 9 v 9 10 <0xc3> 10 11 <0xaa> 11 12 q 12 13 u 13 14 e 14If the user specifies token_type="utf8" then each arc in the FST corresponds to a Unicode codepoint.
# UTF-8 bytestring, Unicode codepoint arcs.
print pynini.acceptor("Pont l'Evêque", token_type="utf8")
# Output below...
0 1 P 1 2 o 2 3 n 3 4 t 4 5 <SPACE> 5 6 l 6 7 ' 7 8 E 8 9 v 9 10 <0xea> 10 11 q 11 12 u 12 13 e 13Sequences of characters enclosed by
[ and ] receive special interpretations in byte or utf8 mode. Pynini first attempts to parse any such sequence as an integer using the C standard library function strtoll.
assert pynini.acceptor("b0x61") == pynini.acceptor("baa") # OK.
If this fails, then Pynini treats the sequence as a sequence of one or more whitespace-delimited "generated" symbols, each of which is given a unique identifier in the resulting FST's symbol table.
x = pynini.acceptor("[It's not much of a cheese shop really]")
y = pynini.acceptor("[It's][not][much][of][a][cheese][shop][really]")
assert x == y # OK.
A bracket character to be interpreted literally must be escaped.
bracket = pynini.acceptor("[") # OK.
unused = pynini.acceptor("[") # Not OK: Raises FstStringCompilationError.
Finally, if the user specifies a SymbolTable as the token_type, then the input string is parsed according and the FST labeled according to that table. String parsing failures are logged and raise a FstStringCompilationError exception from within the Python interpreter.
Nearly all FST operations permit a string to be passed in place of an Fst argument; in that case, pynini.acceptor is used (with default arguments) to compile the string into an FST.
Constructing transducers
Thetransducer function creates a transducer from two FSTs, compiling string arguments into FSTs if necessary. The result is a cross-product of the two input FSTs, interpreted as acceptors. Specifically, the transducer is constructed by mapping output arcs in the first FST to epsilon, mapping the input arcs in the second FST to epsilon, then concatenating the two. In the case that both FSTs are strings, the resulting transducer will simply contain the input and output string converted into labels, and the shorter of the two will be padded with epsilons.
As with acceptor, the user may specify a final weight using the weight keyword argument; the final weight is 1. The user also specify the desired arc type using the arc_type keyword argument. The user may also specify how the characters in the input and/or output strings are to be translated into labels of the transducer, if strings are passed in place of FST arguments. By default (input_token_type="byte" and output_token_type="byte"), each arc corresponds to a byte in the input and/or output string.
Whereas transducer is used to construct the cross-product of two strings, the union of many such string pair cross-products is compiled using the string_map and string_file functions. The former takes an iterable of pairs of strings (or a string-to-string dictionary) as an argument; the latter reads string pairs from two-column TSV filearc_type keyword argument. And as with transducer, the user may also specify how the characters in the input and/or output strings are to be translated into labels of the transducer using the appropriate keyword arguments.
Worked examples
The following examples, taken from Gorman 2016 and Gorman & Sproat 2016, show features of Pynini in action.Finnish vowel harmony
Koskenniemi (1983) provides a number of manually-compiled FSTs modeling Finnish morphophonological patterns. One of these concerns the well-known pattern of Finnish vowel harmony. Many Finnish suffixes have two allomorphs differing only in the backness specification of their vowel. For example, the adessive suffix is usually realized as -llä [lːæː] except when the preceding stem contains one of u, o, and a and there is no intervening y, ö, or ä; in this case, it is -lla [lːɑː]. For example, käde 'hand' has an adessive kädellä, whereas vero 'tax' forms the adessive verolla because the nearest stem vowel is o (Ringen & Heinämäki 1999). The following gives a Pynini functionmake_adessive which generates the appropriate form of the noun stem. It first concatenates the stem with an abstract representation of the suffix, and then composes the result with a context-dependent rewrite rule adessive_harmony.
back_vowel = pynini.union("u", "o", "a")
neutral_vowel = pynini.union("i", "e")
front_vowel = pynini.union("y", "ö", "ä")
vowel = pynini.union(back_vowel, neutral_vowel, front_vowel)
archiphoneme = pynini.union("A", "I", "E", "O", "U")
consonant = pynini.union("b", "c", "d", "f", "g", "h", "j", "k", "l", "m", "n",
"p", "q", "r", "s", "t", "v", "w", "x", "z")
sigma_star = pynini.union(vowel, consonant, archiphoneme).closure()
adessive = "llA"
intervener = pynini.union(consonant, neutral_vowel).closure()
adessive_harmony = (pynini.cdrewrite(pynini.transducer("A", "a"),
back_vowel + intervener, "", sigma_star) *
pynini.cdrewrite(pynini.t("A", "ä"), "", "", sigma_star)
).optimize()
def make_adessive(stem):
return ((stem + adessive) * adessive_harmony).stringify()
Pluralization rules
Consider an application where one is generating text such as, "The current temperature in New York is 25 degrees". Typically one would do this from a template such as the following:The current temperature in __ is __ degreesThis works fine if one fills in the first blank with the name of a location and the second blank with a number. But what if its really cold in New York and the thermometer shows 1° (Fahrenheit)? One does not want this:
The current temperature in New York is 1 degreesSo one needs to have rules that know how to inflect the unit appropriately given the context. The Unicode Consortium has some guidelines
singular_map to handle irregular cases, plus the general cases:
singular_map = pynini.union(
pynini.transducer("feet", "foot"),
pynini.transducer("pence", "penny"),
# Any sequence of bytes ending in "ches" strips the "es";
# the last argument -1 is a "weight" that gives this analysis
# a higher priority, if it matches the input.
sigma_star + pynini.transducer("ches", "ch", -1),
# Any sequence of bytes ending in "s" strips the "s".
sigma_star + pynini.transducer("s", ""))
Then as before we can define a context-dependent rewrite rule that performs the
singularization just in case the unit is preceded by 1. We define the right
context for the application of the rule rc as punctuation, space, or [EOS], a
special symbol for the end-of-string.
rc = pynini.union(".", ",", "!", ";", "?", " ", "[EOS]")
singularize = pynini.cdrewrite(singular_map, " 1 ", rc, sigma_star)
Then we can define a convenience function to apply this rule...
def singularize(string):
return pynini.shortestpath(
pynini.compose(string.strip(), singularize)).stringify()
...and use it like so:
>>> singularize("The current temperature in New York is 1 degrees")
"The current temperature in New York is 1 degree"
>>> singularize("That measures 1 feet")
"That measures 1 foot"
>>> singularize("That measures 1.2 feet")
"That measures 1.2 feet"
>>> singularize("That costs just 1 pence")
"That costs just 1 penny"
One can handle other languages by changing the rules appropriately—for example, in Russian, which has http://www.unicode.org/cldr/charts/29/supplemental/language_plural_rules.htmlT9 disambiguation
T9 (short for "Text on 9 keys"; Grover et al. 1998) is a patented predictive text entry system. In T9, each character in the "plaintext" alphabet is assigned to one of the 9 digit keys (0 is usually reserved to represent space) of the traditional 3x4 touch-tone phone grid. For instance, the message GO HOME is entered as 4604663. Since the resulting "ciphertext" may be highly ambiguous—this sequence could also be read as GO HOOD or as many nonsensical expressions—a hybrid language model/lexicon is used for decoding. The following snippet implements T9 encoding and decoding in Pynini:
LM = pynini.Fst.read("charlm.fst")
T9_ENCODER = pynini.string_file("t9.tsv").closure()
T9_DECODER = pynini.invert(T9_ENCODER)
def encode_string(plaintext):
return (plaintext * T9_ENCODER).stringify()
def k_best(ciphertext, k):
lattice = (ciphertext * T9_DECODER).project(True) * LM
return pynini.shortestpath(lattice, nshortest=k, unique=True)
The first line reads a language model (LM), represented as a WFSA. The second line reads the encoder table from a TSV file: in this file, each line contains an alphabetic character and the corresponding digit key. By computing the concatenative closure of this map, one obtains an FST T9_ENCODER which can encode arbitrarily-long plaintext strings. The encode_string function applies this FST to arbitrary plaintext strings: application here refers to composition of a string with a transducer followed by output projection. The
k_best function first applies a ciphertext string—a bytestring of digits—to the inverse of the encoder FST (T9_DECODER). This creates an intermediate lattice of all possible plaintexts consistent with the T9 ciphertext. This is then scored with—that is, composed with—the character LM. Finally, this function returns the k highest probability plaintexts in the lattice. For the following example, the highest probability plaintext is in fact the correct one:
pt = "THE SINGLE MOST POPULAR CHEESE IN THE WORLD" ct = encode_string(pt) print "CIPHERTEXT:", ct print "DECIPHERED PLAINTEXT:", k_best(ct, 1).stringify() ---+ Output below...
CIPHERTEXT: 8430746453066780767852702433730460843096753 DECIPHERED PLAINTEXT: THE SINGLE MOST POPULAR CHEESE IN THE WORLD
Advanced topics
Getting the hang of iterators
TheFst class provides four types of iterators (plus SymbolTableIterator), which are usually constructed by invoking the appropriate method of Fst. Some
examples are given below.
There are two ways to use the various iterators. First, they can be used similarly to Python built-in iterators over file handles or containers by placing them in a =for=-loop, but they also expose a lower-level interface used as follows:
while not iterator.done(): # Do something with =iterator= in its current state. iterator.next() # Advances the iterator.Attempting to use an iterator which is "done" may result in a fatal error. To return an iterator to the initial state, one can use the
reset method.
The method states creates a StateIterator. When iterated over, it yields state ID integers in strictly increasing order. For example, the following function computes the number of arcs and states of an FST (a simple measure of FST size).
def size(f): """Computes the number of arcs and states in the FST.""" return sum(1 + f.num_arcs(state) for state in f.states())The method
arcs returns an ArcIterator. When iterated over, it yields all arcs leaving some state of the FST. For example, the following function computes the in-degree (number of incoming states) for a given state ID.
def indegree(f, state):
"""Computes in-degree of some state in an FST."""
n = 0
for s in f.states():
for arc in f.arcs(s):
n += (arc.nextstate == state)
return n
The method mutable_arcs is similar to arcs, except that the MutableArcIterator it returns has a special method set_value which replaces the arc at the iterator's current position. For example, the following function changes input labels matching a certain label to epsilon (cf. the relabel_pairs method).
def map_ilabel_to_epsilon(f, ilabel):
"""Maps any input label matching =ilabel= to epsilon (0)."""
for state in f.states():
aiter = f.mutable_arcs(state)
while not aiter.done():
arc = aiter.value()
if arc.ilabel == ilabel:
arc.ilabel = 0
aiter.set_value(arc)
aiter.next()
return f
The method paths returns a StringPaths iterator. This provides several ways to access the paths of an acyclicilabels and olabels methods, the input and output strings via the istring and ostring methods, and the path weight via the weight method. One can also access all input strings, all output strings, and all path weights using the iter_istrings, iter_ostrings, and iter_weights methods, which return generators; after invoking any one of these methods, the caller must reset the iterator to reuse it.
See in-module documentation strings for more information on iterators.
FST properties
EachFst has an associated set of stored properties which assert facts about the FST. These can be queried by using the properties method. Some properties are binary (either true or false), whereas others are ternary (true, false, or unknown). The first argument to properties is a bitmask for the desired property/properties, and the second argument indicates whether unknown properties are to be computed.
Querying known properties is a constant time operation.
# Optimizes the FST if it is *not known* to be deterministic. if f.properties(pynini.I_DETERMINISTIC, False) != pynini.I_DETERMINISTIC: f.optimize()Computing unknown properties is linear in the size of the FST in the worst case.
# Optimizes the FST if it is not already deterministic and epsilon-free. desired_props = pynini.I_DETERMINISTIC | pynini.NO_EPSILONS if f.properties(desired_props, True) != desired_props: f.optimize()An FST's properties can be set using the
set_properties method.
For more information on FST properties, see hereCreating FSTs manually
Fst (which happens to be the constructor for the Fst class) creates an FST with no states or arcs. Before this FST can be used, one must first add a state, set it as initial, and set it or some other state as final.
f = pynini.Fst() assert not f.verify() # OK. state = f.add_state() f.set_start(state) f.set_final(state) assert f.verify() # OK.The
epsilon_machine function eliminates the need for this tedious book-keeping; it returns a one-state, no-arc machine.
A much more useful initialization is provided by epsilon_machine, which creates a one-state, no-arc acceptor which matches the empty string.
f = pynini.epsilon_machine() assert f.num_states() == 0 # OK. assert f.num_arcs(e.start()) == 0 # OK. assert f.final(e.start()) == pynini.Weight.One(f.weight_type()) # OK.In general, attempting to refer to a state before it has been added to the FST will raise an
FstIndexError.
f = pynini.epsilon_machine() f.set_start(1) # Not OK: Raises FstIndexError.
f = pynini.epsilon_machine() f.set_final(1) # Not OK: Raises FstIndexError.
f = pynini.epsilon_machine() f.add_arc(1, Arc(65, 65, 0, f.start())) # Not OK: Raises FstIndexError.The one exception to this generalization is that one may add an arc to a destination state not yet added to the FST, though the FST will not
verify until that state is added.
f = pynini.epsilon_machine() f.add_arc(f.start(), pynini.Arc(65, 65, 0, 1)) assert not f.verify() # OK, though arc has non-existent destination state ID. state = f.add_state() # OK, now that state exists. f.set_final(state) assert f.verify() # OK.
Pushdown transducers and multi-pushdown transducers
Pushdown transducers (PDTs)Fst and a table of parentheses labels. The PdtParentheses object contains pairs of open/close parentheses labels, and the MPdtParentheses object also contains an integer representing the identity of the stack each parentheses pair is assigned to.
PDTs and MPDT support composition with an FST using the pdt_compose and mpdt_compose functions, respectively. These functions take Fst arguments, a parentheses table (PdtParentheses or MPdtParentheses, respectively), and a specification of whether the right or the left argument should be interpreted as a (M)PDT. Both functions return the FST component of an (M)PDT; the parentheses table can be reused.
(f, fparens) = ipdt opdt = (pynini.pdt_compose(f, g, fparens), fparens)The
pdt_expand and mpdt_expand functions can be used to expand a PDT or MPDT into an FST (assuming they have a finite expansion). They take an Fst and parentheses table and return an Fst. The boolean keep_parentheses argument species whether or not expansion should keep parentheses arcs; by default, they are removed during expansion.
(f, fparens) = ipdt g = pynini.pdt_expand(f, fparens)The
pdt_reverse and mpdt_reverse functions can be used to reverse a PDT or MPDT. Both take as arguments the two components of an (M)PDT. The pdt_reverse function return the FST component of a PDT, whereas the mpdt_function also returns a modified MPdtParentheses object.
(f, fparen) = impdt (g, gparens) = pynini.mpdt_reverse(f, fparens)Finally, PDTs (but not MPDTs) provide a shortest-path operation using
pdt_shortestpath. Note that the result is an FST rather than a PDT.
(f, fparens) = ipdt sp = pynini.pdt_shortestpath(f, fparens)
References
Gorman, Kyle. 2016. Pynini: A Python library for weighted finite-state grammar compilationTopic revision: r2 - 2017-06-30 - KyleGorman
|
|
Ideas, requests, problems regarding TWiki? Send feedback